
Neuroscience Study
미래로 가는 여행 본문
모든 각각의 결정은 우리의 과거 경험(우리의 신체 상태 안에 저장되어 있음) 및 현재 상황(Y가 아니라 X를 사기에 충분한 돈이 내게 있나? Z도 선택 가능할까?)과 관련이 있다. 그런데 결정에 관여하는 요소가 하나 더 있다. 그것은 미래에 관한 예측이다.
모든 동물은 보상을 추구하도록 설계되어 있다. 보상이란 무엇일까? 핵심을 말하면, 보상은 몸을 이상적인 설정 값들에 더 접근시키는 무언가를 뜻한다. 당신의 몸이 건조해질 때 물은 보상이다. 당신의 에너지 저장량이 고갈되어갈 때 먹을거리는 보상이다. 물과 먹을거리는 '일차적 보상'이라고 불린다. 일차적 보상은 생물학적 욕구들에 직접 부응한다. 그러나 더 일반적으로 인간의 행동은 이차적 보상들에 의해 조종된다. 예컨대 금속으로 된 사각형의 모습 그 자체는 당신의 뇌에 별다른 영향을 미치지 못하겠지만, 당신은 그 모습을 물통으로 인지하는 법을 학습했기 때문에, 당신이 목마를 때 그 모습은 보상이 된다. 인간에게는 매우 추상적인 개념조차도 보상일 수 있다. 이를테면 우리가 속한 지역 공동체가 우리를 소중히 여긴다는 느낌은 보상이 된다. 또한 동물과 달리 우리는 이런 보상을 생물학적 욕구보다 앞세울 수 있다. 리드 몬터규의 말마따나 '상어는 단식투쟁을 하지 않는다.” 우리를 제외한 동물계 전체는 오로지 기본적인 욕구들을 추구하는 반면, 인간들은 흔히 추상적 이상을 옹호하면서 기본 욕구를 외면한다. 요컨대 우리가 다양한 선택지들을 마주했을 때, 우리는 내적인 데이터와 외적인 데이터를 종합하여 보상을 (우리 각자에게 무엇이 보상이든지 간에) 극대화하려고 애쓴다.

기본적이든 추상적이든 상관없이 모든 보상에 동반되는 걸림돌은, 대개 선택의 결실이 곧바로 주어지지 않는다는 점이다. 거의 항상 우리는 결정을 내리고 행동하고 나서 나중에 보상을 받는다. 사람들은 미래에 학위를 따는 것에 가치를 두기 때문에 몇 년 동안 학교에 다니고, 미래에 승진하리라는 희망을 품었기 때문에 하기 싫은 직장 생활을 버텨내며, 멋진 몸매를 목표로 세웠기 때문에 힘겨운 운동을 마다하지 않는다.
다양한 선택지들을 비교한다는 것은 각각의 선택지에 공통 단위로 매긴 가치(예상되는 보상의 가치)를 부여한 다음에 가치가 가장 높은 선택지를 고른다는 뜻이다. 이런 시나리오를 생각해보자. 나는 여유 시간이 조금 생겨서 무엇을 할지 결정하려고 한다. 나는 식료품을 사야 한다. 하지만 다른 한편으로 카페에 가서 내 실험실을 위한 연구비 신청서를 작성해야 한다는 것도 안다. 신청서 제출 마감일이 임박했기 때문이다. 게다가 나는 아들과 공원에서 시간을 보내고 싶다. 나는 이 선택지들 가운데 하나를 어떻게 골라야 할까?
당연한 말이지만, 내가 각각의 선택지를 실제로 취해보고 직접 비교한 다음에 시간을 되돌려 지금으로 돌아올 수 있다면, 선택은 쉬운 일일 것이다. 그러나 안타깝게도 나는 시간 여행을 할 수 없다.
아니, 어쩌면 할 수 있을까?
실제로 인간의 뇌는 끊임없이 시간 여행을 한다. 결정을 내려야 할 때, 우리의 뇌는 다양한 결과들을 시뮬레이션하여 미래의 모형을 제작한다. 정신적인 측면에서 말하면, 우리는 현재를 떠나 아직 존재하지 않는 세계로 여행할 수 있다.
자, 내 정신 속에서 한 시나리오를 시뮬레이션하는 것은 첫걸음에 불과하다. 상상한 시나리오들 중에 하나를 선택하기 위해서 나는 그 잠재적 미래들 각각에서 얼마나 큰 보상이 주어질지 추정한다. 나의 주방 수납장을 식료품으로 채우는 것을 시뮬레이션할 때, 나는 알뜰한 가사 운영으로 불확실성을 피하는 것에서 안도감을 느낀다. 연구비는 다른 유형의 보상이다. 그것은 실험실을 위한 자금일 뿐 아니라 더 일반적으로 내가 속한 학과의 우두머리에게서 받는 칭찬이며 과학자로서 성취감을 안겨주는 상이다. 공원에서 아들과 노는 것을 상상하면 기쁨이 일어나고 가족 간의 친밀감이라는 형태의 보상이 느껴진다. 최종 선택은 보상 시스템들이 통용하는 공통 통화로 측정할 때 각각의 미래가 얼마나 큰 가치를 가졌느냐를 기준으로 이루어질 것이다. 물론 쉽지 않은 선택이다. 언급한 선택지들 모두에 미묘한 단점이 뒤따르기 때문이다. 식료품 구입의 시뮬레이션은 권태감을 동반한다. 연구비 신청서 작성은 불만감을 일으킨다. 공원에서 노는 상상은 할 일을 안 한다는 죄책감을 동반한다. 대개 의식적 자각의 레이더가 미치는 층위보다 더 낮은 층위에서 나의 뇌는 이 모든 선택지들을 하나씩 시뮬레이션하고 평가한다. 이것이 내가 결정을 내리는 방식이다.
어떻게 나는 이 미래들을 정확히 시뮬레이션할까? 각각의 경로로 들어서면 실제로 어떤 결과가 나올지를 나는 어떻게 예측할 수 있을까? 나는 정확한 시뮬레이션을 할 수 없고 실제 결과를 예측할 수 없다는 것이 정답이다. 나의 예측이 정확하리라는 것을 알 길은 없다. 내가 하는 모든 시뮬레이션은 나의 과거 경험들과 세계의 작동에 대한 나의 현재 모형들에 기초를 둘 뿐이다. 동물계의 모든 동물들과 마찬가지로, 우리는 무엇이 미래에 보상을 가져오고 무엇이 그렇지 않은지 무작위로 발견하리라는 희망을 품고 마냥 돌아다닐 수는 없다. 오히려 뇌의 핵심 임무는 예측이다. 예측을 잘하려면, 모든 경험을 토대로 끊임없이 세계에 대해서 배울 필요가 있다. 앞서 언급한 예에서, 나는 과거 경험에 기초하여 선택지 각각에 가치를 부여한다. 할리우드 영화들에 빗대어 말하면, 우리는 상상 속의 미래가 얼마나 큰 가치를 가질지 알아보려고 그 미래로 시간 여행을 떠난다. 이것이 내가 가능한 미래들을 비교하고 선택하는 방식이다. 이것이 내가 경쟁하는 선택지들을 미래의 (공통 통화로 따진) 보상으로 변환하는 방식이다.
각각의 선택지에 대해서 내가 예측한 보상을 그 선택지의 결과물이 얼마나 좋을지에 대한 내적인 평가로 볼 수 있다. 식료품 구입은 나에게 먹을거리를 제공할 것이므로, 이 선택지의 가치는 보상 단위로 따져서 이를테면 10이라고 해보자. 연구비 신청서 작성은 어렵지만 나의 경력에 필수적이므로 25 보상 단위의 가치가 있다. 나는 아들과 시간을 보내는 것을 매우 좋아하므로 공원에 가는 것은 50 보상 단위의 가치가 있다.
하지만 이 대목에서 흥미로운 비틀림이 일어난다. 세계는 복잡하기 때문에, 우리의 내적인 평가는 결코 영구적으로 확정되지 않는다. 주변의 모든 것에 대한 당신의 가치 평가는 가변적이다. 왜냐하면 우리의 예측과 실제 사건이 일치하지 않는 일이 무척 흔하기 때문이다. 효과적인 학습의 열쇠는 그런 예측 오류(한 선택의 예측된 결과와 실제로 발생한 결과 사이의 차이)를 추적하는 것에 있다.
나의 뇌는 공원에서 놀기가 얼마나 큰 보상을 가져올지 예측한다. 만일 나와 아들이 공원에서 우연히 친구들을 만나서 내가 생각한 것보다 더 즐거운 시간을 보낸다면, 다음번에 유사한 결정을 내릴 때 이 선택지에 대한 평가 값은 올라갈 것이다. 반대로 공원에 갔는데 그네는 망가져 있고 비만 추적추적 내린다면, 다음번에 나의 평가 값은 내려갈 것이다.
이런 평가 값 조정은 어떻게 일어날까? 뇌 속에는 아주 작고 오래된 시스템 하나가 있다. 그것의 임무는 세계에 대한 당신의 평가 값들을 끊임없이 갱신하는 것이다. 이 시스템은 당신의 중간뇌midbrain에 있는 아주 작은 세포 집단들로 이루어졌다. 그 세포들은 '도파민'이라는 신경전달물질을 통해서 다른 세포들에 정보를 전달한다.
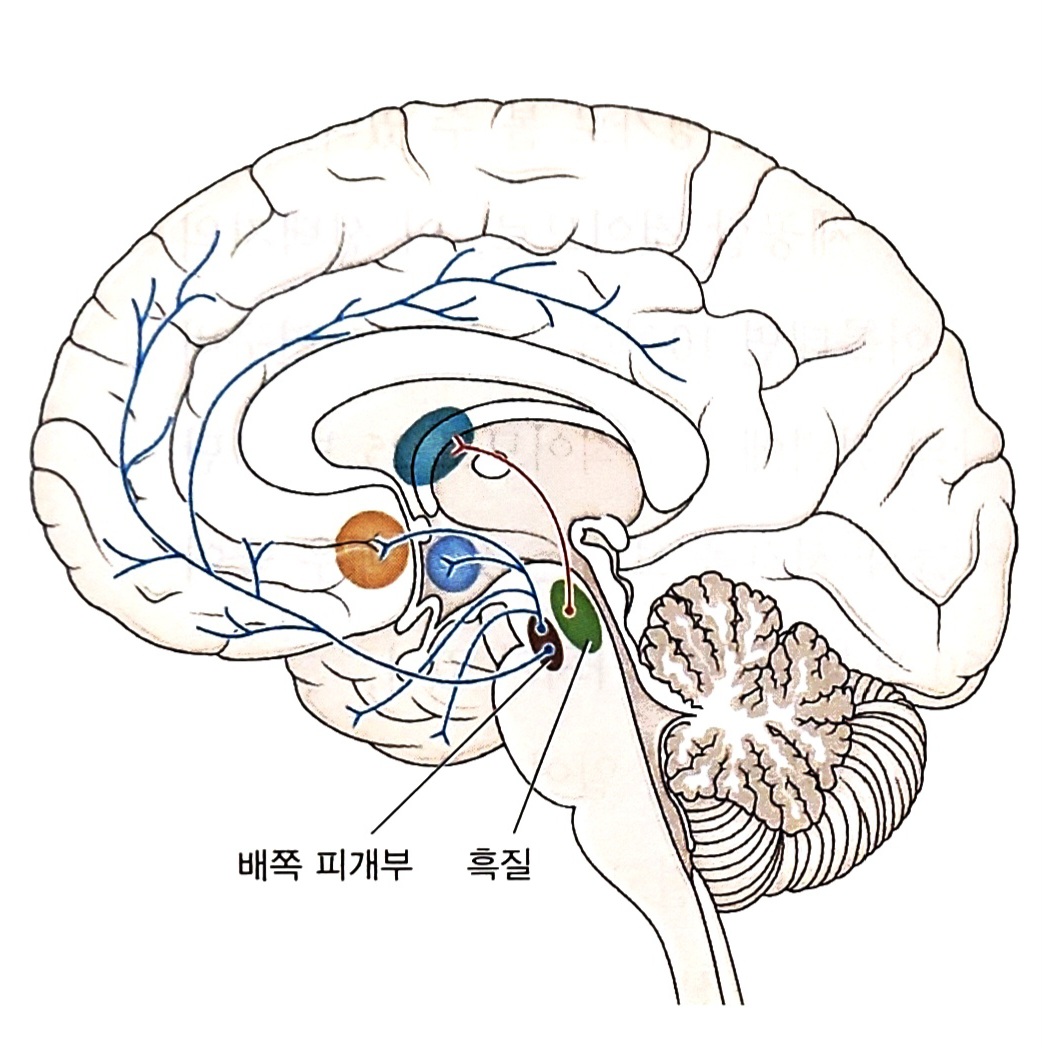
당신의 예측과 실재 사이에 불일치가 있으면, 이 중간뇌 도파민 시스템은 신호를 퍼뜨려 평가 값을 재설정한다. 이 신호는 실제 결과가 예상보다 더 좋은지(도파민 분출량 증가) 아니면 더 나쁜지(도파민 감소) 뇌의 나머지 부분에 알려준다. 이런 예측 오류 신호 덕분에 뇌의 나머지 부분은 다음번에는 실재와 더 잘 일치하도록 예측을 조정할 수 있다. 이처럼 도파민은 오류 수정자 구실을 한다. 다시 말해, 도파민은 당신의 평가 값들을 최대한 최신화하는 일을 항상 수행하는 화학적 감정평가사인 셈이다. 이런 식으로 당신은 미래에 관한 최적의 예측에 기초하여 당신의 선택지들에 우선순위를 매길 수 있다.
기본적으로 뇌는 예상 밖의 결과들을 감지하도록 설계되어 있다. 이 민감성은 동물의 적응 및 학습 능력의 핵심에 놓여 있다. 따라서 경험을 통한 학습에 관여하는 뇌 구조물들이 종의 차이를 막론하고 꿀벌부터 인간까지 한결같다는 것은 놀라운 사실이 아니다. 이 일관성은 뇌가 보상에 기초한 학습의 기본 원리들을 오래전에 발견했음을 시사한다.
데이비드 이글먼. (2017). 더 브레인 (전대호, 역). 서울: 해나무.
'Neuroscience Book > Neuroscience' 카테고리의 다른 글
| 우리 각자의 절반은 타인들이다 (1) | 2022.11.26 |
|---|---|
| 보이지 않는 결정 메커니즘들 (0) | 2022.11.25 |
| 뇌는 분쟁에 기초하여 작동하는 기계다 (0) | 2022.11.24 |
| 무의식의 깊은 동굴들 (0) | 2022.11.23 |
| 행동의 자동화 (0) | 2022.11.23 |



